Abaqus
Abaqus is a computer aided engineering suite based on finite element analysis.
Licensing
CHPC utilizes a license co-owned by several Mechanical Engineering Department groups.
One has to be a member of one of these groups in order to use the program. If you
don't have an access to Abaqus, please, let us know, we will work with you on what options you may have to use it.
For the current Abaqus users, it is important to observe the license usage and not submit batch jobs when licenses are close to being used fully. Abaqus suite components wait for a license to free before they proceed, which results in the batch job waiting, while occupying the compute nodes. Please see the following webpage for the current license usage.
Abaqus uses a non-linear task vs. token count checked out model, which is as follows :
Using the Open OnDemand web portal
The Open OnDemand web portal allows to start the Abaqus GUI from a web browser. Choose the Abaqus app in the OnDemand web interface, fill in the appropriate job parameters and push the Launch button. A job will be submitted and once it starts a new browser tab with Abaqus GUI will start.
Note that the Abaqus session is persistent, that is, it does not terminate when the Abaqus browser tab is closed. Once can connect back to the Abaqus session by locating it in the OnDemand active sessions list.
To quit Abaqus, close the browser tab AND delete the job in the OnDemand active sessions list.
Using the GUI
The GUI approach allows one to design and build the simulation, and then potentially run it from the GUI. However, in order to run one generally needs more compute resources which is better done through a batch job.
To run the GUI, we recommend using the Frisco interactive nodes. Log into those using FastX remote desktop, open a terminal and run
module load abaqus
abaqus cae
An Abaqus window appears that allows one to load, set up or modify a simulation.
Using batch
Running simulation in the batch is preferred for several reasons. First, one can use more than one node, which may speed up the simulation or make it feasible due to larger memory availability. Second, the job will wait in the SLURM queue till the resources are available, and start without the need of user interaction.
Abaqus has several different ways to run in batch.
The first one uses an input file, usually named *.inp, or *.cae. This file is used as one of the inputs to the abaqus command. In the command line one can specify run parameters, such as parallelization method and CPU count.
The second option is to use a Python script, which contains a "recipe" on how to create the input file and how to run the simulation. While the Python script approach is attractive with respect to automation potential of the input creation, one has to be careful on defining the compute resources so that those specified in the Python script match those requested in the SLURM job script.
An example Abaqus SLURM job script is abaqus_kingspeak.csh. This script uses one of the Abaqus examples as an input, though modifying the JOBNAME
environment variable will allow one to use their own input. Note that the results
will be stored in the scratch directory. It is set up to run on kingspeak guest nodes,
change the account and partition to your preferred cluster and account. You can use
the command myallocation to see what accounts/partitions you have available.
Make sure that you unset SLURM environment variable SLURM_GTIDS , failure to do so will cause the Abaqus run to get stuck due to the MPI that Abaqus
ships with not supporting the SLURM scheduler.
Abaqus 2022 also ships with a version of Intel MPI that has a bug which surfaces on
our cluster systems. To work around this bug, set environment variable I_MPI_HYDRA_TOPOLIB=ipl . Additionally, in order to utilize SLURM to run a multi-node calculation, one needs
to set environment variable I_MPI_HYDRA_BOOTSTRAP=slurm .
Abaqus has two parallelization options which are mutually exclusive, MPI and THREADS.
Using MPI is generally preferred since this allows for scaling the job to multiple
compute nodes. The option to set the parallelization is mp_mode , e.g. mp_mode=mpi. However, be aware of the efficiency of the parallelization by checking the job's
performance, as described below.
Once the input file and the script are ready, submit the job as
sbatch abaqus_kingspeak.csh
You can monitor the status of the job with
squeue -u myUNID
myUNID being your uNID.
Once the job starts, it is important to check the simulation and SLURM output files to ensure that the job is not waiting for a license, or that it is well parallelized. Also, utilize the pestat command to check if the compute nodes of your job are well utilized.\
Runtime problems
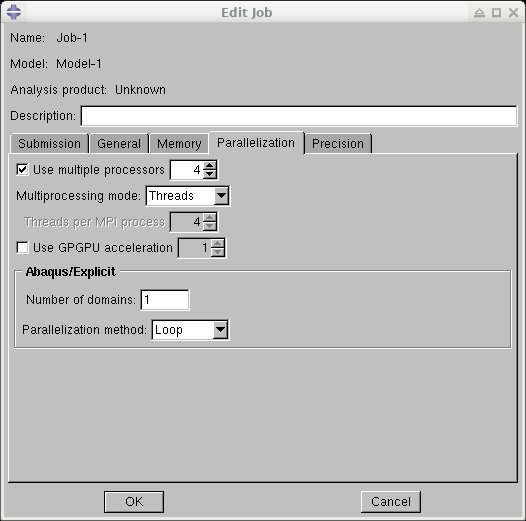
We have observed that the Explicit parallel simulation crash if there is a small number of elements in a domain and it is impossible to partition the domain onto multiple parallel tasks. In that case there are tasks which don't have any elements which causes to crash. The workaround is to either reduce the number of parallel tasks to correspond to the number of domains with non-zero element count, or use the thread (sometimes called loop) parallelization.
Note that the default MPI parallelization is more efficient so only use the threading parallelization if the MPI parallelization does not work.
To turn on the threading parallelization, using command line:
abaqus job=my_model cpus=$SLURM_NTASKS mp_mode=threads
Or, in the CAE GUI: